Trong kỷ nguyên chuyển đổi số, Thị giác Máy tính (Computer Vision) đang trở thành một trong những nhánh quan trọng nhất của Trí tuệ Nhân tạo (AI). Nhiều bài toán hiện đại như xe tự hành, chẩn đoán hình ảnh y khoa, phân tích hành vi từ camera hay giám sát an ninh đều phụ thuộc vào khả năng máy tính nhận biết và hiểu nội dung hình ảnh. Cốt lõi của bước tiến này đến từ Deep Learning, đặc biệt là kiến trúc Mạng Nơ-ron Tích chập (CNN).
CNN được xem như nền tảng của hầu hết hệ thống nhận dạng hình ảnh hiện đại nhờ khả năng tự động trích xuất đặc trưng và học biểu diễn theo cấp bậc (từ cạnh, góc đến hình dạng và đối tượng). Báo cáo này được biên soạn như một tài liệu tham khảo mang tính học thuật, phù hợp cho sinh viên đại học – sau đại học và phục vụ mục tiêu giảng dạy, nghiên cứu tại Việt Nam. Nội dung được hệ thống hóa theo lộ trình: lý thuyết → thực hành → tối ưu nâng cao, với hai bộ dữ liệu kinh điển là MNIST và Fashion-MNIST.
Nội dung
- 1 Cơ sở lý thuyết và toán học của CNN
- 2 Vì sao MLP không phù hợp với ảnh?
- 3 Phép tích chập (Convolution Operation)
- 4 Hàm kích hoạt: đưa phi tuyến vào mô hình
- 5 Pooling layer: giảm chiều và tăng bất biến dịch chuyển
- 6 Fully Connected và Softmax: bước ra quyết định phân loại
- 7 Ví dụ: MNIST và bước khởi đầu chuẩn hóa
Cơ sở lý thuyết và toán học của CNN
Động lực sinh học và sự ra đời của CNN
CNN không xuất hiện ngẫu nhiên mà được truyền cảm hứng từ vỏ não thị giác ở động vật có vú. Nghiên cứu của Hubel và Wiesel (thập niên 1950–1960) cho thấy hệ thị giác xử lý hình ảnh theo cấu trúc phân cấp:
- Simple cells phản ứng với kích thích cục bộ trong một vùng nhỏ (receptive field), ví dụ cạnh ngang/dọc.
- Complex cells tổng hợp thông tin từ nhiều vùng để nhận diện mẫu lớn hơn và tạo ra tính bất biến với dịch chuyển nhỏ.
Tinh thần này được CNN kế thừa thông qua hai nguyên lý quan trọng:
- Kết nối cục bộ (local connectivity): neuron chỉ nhìn một vùng nhỏ thay vì toàn ảnh.
- Chia sẻ trọng số (parameter sharing): cùng một bộ lọc được dùng trên mọi vị trí ảnh, giúp giảm tham số và tăng khả năng tổng quát hóa.
Vì sao MLP không phù hợp với ảnh?
Một bức ảnh là dữ liệu có cấu trúc không gian rõ ràng. Ví dụ ảnh RGB 200×200 có dạng tensor 200×200×3 với 120.000 giá trị. Nếu đưa vào mạng MLP, ảnh phải được duỗi phẳng thành vector dài, khiến số tham số tăng bùng nổ. Chỉ riêng lớp ẩn đầu tiên 1.000 neuron có thể cần tới hàng trăm triệu trọng số, kéo theo:
- Chi phí tính toán lớn, khó huấn luyện.
- Overfitting nghiêm trọng, mô hình dễ “học thuộc” dữ liệu.
- Mất cấu trúc không gian, vì pixel kề nhau không còn được hiểu là liên quan.
CNN giải quyết trực tiếp các điểm yếu này bằng cơ chế tích chập và học đặc trưng theo vùng.
Phép tích chập (Convolution Operation)
Cơ chế trượt kernel
Trong CNN, “tích chập” thường được triển khai như cross-correlation, tức kernel trượt trên ảnh và tính tổng các tích phần tử tương ứng. Tại mỗi vị trí, kernel đóng vai trò như một “bộ dò đặc trưng” (ví dụ dò cạnh, dò texture). Kết quả tạo thành feature map, thể hiện mức độ “phản ứng” của bộ lọc ở từng vùng ảnh.
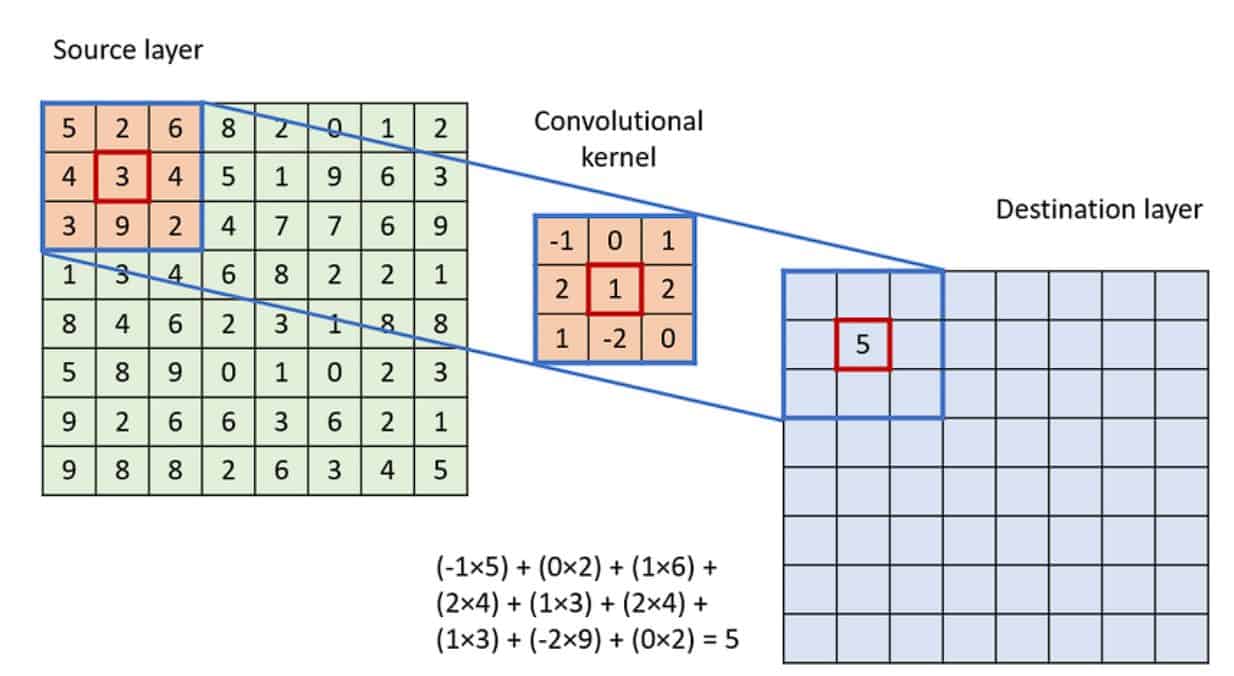
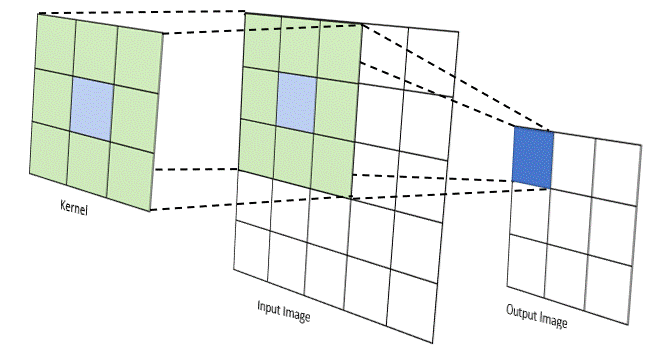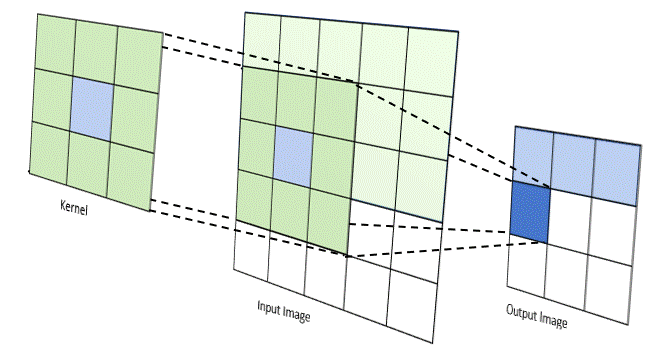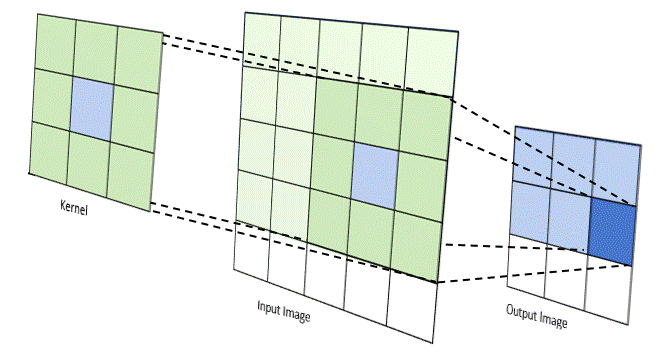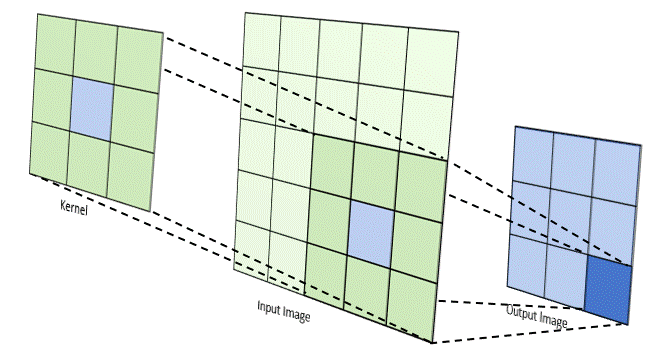
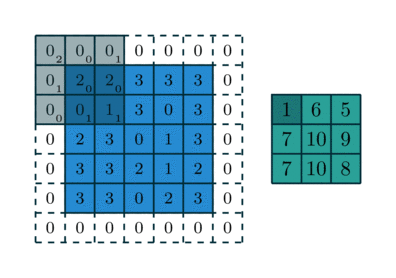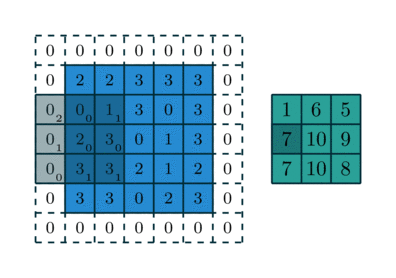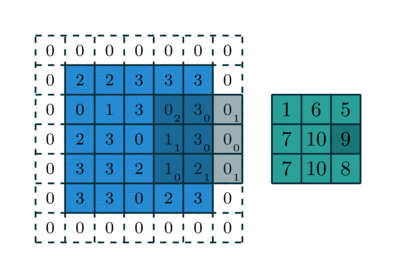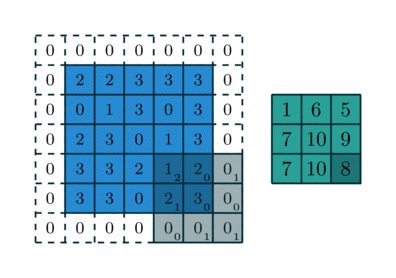
Các siêu tham số quan trọng
Thiết kế lớp convolution phụ thuộc vào các siêu tham số:
- Kernel size: kernel nhỏ (3×3) phổ biến vì hiệu quả và ít tham số.
- Stride: bước nhảy của kernel; stride lớn giúp giảm kích thước nhanh hơn.
- Padding: thêm viền 0 để giữ kích thước hoặc kiểm soát mức co ảnh.
- Dilation: giãn khoảng cách kernel để mở rộng receptive field mà không tăng tham số.
Việc tính kích thước đầu ra qua từng lớp là kỹ năng nền tảng khi xây dựng CNN, giúp kiểm soát cấu trúc mạng và tránh lỗi kích thước tensor.
Hàm kích hoạt: đưa phi tuyến vào mô hình
Tích chập về bản chất là phép biến đổi tuyến tính. Nếu không có phi tuyến, nhiều lớp chồng lên nhau vẫn chỉ tương đương một lớp tuyến tính. Do đó, CNN cần hàm kích hoạt để tăng khả năng biểu diễn.
- Sigmoid/Tanh: từng phổ biến nhưng dễ gây vanishing gradient, làm mạng sâu học rất chậm.
- ReLU: trở thành chuẩn hiện đại nhờ:
- Gradient tốt ở miền dương (giảm vanishing gradient),
- Tạo tính thưa (sparsity) giúp giảm overfitting,
- Tính toán nhanh và đơn giản.
Một số biến thể như Leaky ReLU/ELU hỗ trợ giảm hiện tượng “dying ReLU”.
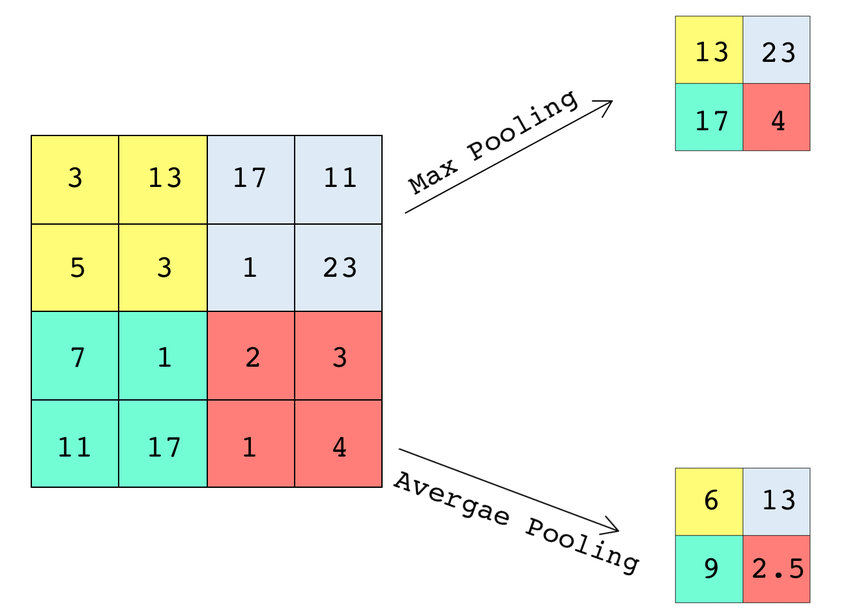
Pooling layer: giảm chiều và tăng bất biến dịch chuyển
Pooling được dùng để giảm kích thước feature map và tăng tính ổn định:
- Giảm tham số và tốc độ tính toán cho các lớp sau.
- Giảm nhiễu, hỗ trợ tổng quát hóa.
- Tạo translation invariance: vật thể dịch chuyển nhẹ vẫn được nhận dạng.
Hai dạng phổ biến:
- Max pooling: giữ đặc trưng nổi bật nhất.
- Average pooling: làm mượt; thường dùng ở dạng Global Average Pooling trong các kiến trúc hiện đại thay cho fully connected.
Fully Connected và Softmax: bước ra quyết định phân loại
Sau chuỗi Conv–ReLU–Pool, tensor đặc trưng (ví dụ 7×7×64) được flatten thành vector và đưa qua các lớp fully connected để kết hợp đặc trưng cấp cao. Lớp cuối thường dùng Softmax để biến logits thành phân phối xác suất trên các lớp, phục vụ bài toán phân loại.
Xu hướng hiện đại là giảm phụ thuộc vào fully connected để hạn chế tham số, thay bằng Global Average Pooling trong các kiến trúc như ResNet.
Ví dụ: MNIST và bước khởi đầu chuẩn hóa
MNIST gồm 70.000 ảnh xám 28×28 chữ số viết tay, được coi là “Hello World” của Deep Learning. Với CNN đơn giản (phong cách LeNet hiện đại hóa), mô hình có thể đạt ~98.5–99.2% accuracy, giúp người học nắm quy trình:
- tiền xử lý dữ liệu,
- thiết kế kiến trúc,
- huấn luyện với tối ưu Adam và CrossEntropyLoss,
- đánh giá trên test set.
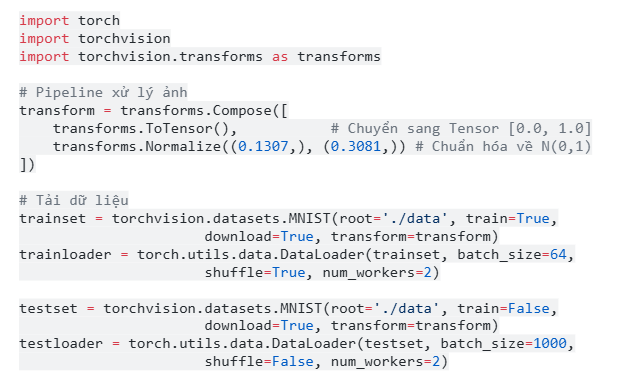
Bước 1: Chuẩn bị dữ liệu
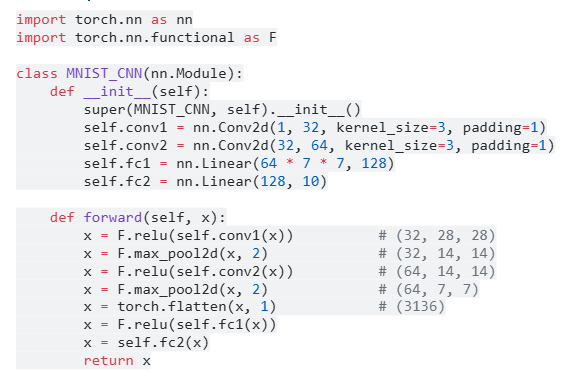
Bước 2: Kiến trúc CNN
Bước 3: Huấn luyện

Kết quả kỳ vọng: ~97%–99% accuracy trên test set.
CNN là bước tiến lớn giúp máy tính mô phỏng thị giác sinh học và xử lý hình ảnh hiệu quả. Từ nguyên lý tích chập – pooling – phi tuyến đến triển khai thực tế trên MNIST và tối ưu cho Fashion-MNIST, CNN chứng minh khả năng học đặc trưng mạnh mẽ và tính ứng dụng rộng. Lộ trình “hiểu lý thuyết → làm được mô hình → tối ưu để tốt hơn” là nền tảng thiết yếu cho bất kỳ ai theo đuổi AI và Computer Vision.
Giảng viên Hoàng Đức Quang
| FPT Aptech trực thuộc Tổ chức Giáo dục FPT có hơn 25 năm kinh nghiệm đào tạo lập trình viên quốc tế tại Việt Nam, và luôn là sự lựa chọn ưu tiên của các sinh viên và nhà tuyển dụng. |


