Trong kỷ nguyên công nghệ 4.0, trí tuệ nhân tạo (AI) đã trở thành nền tảng của hầu hết các ứng dụng hiện đại, từ nhận diện khuôn mặt, giọng nói cho đến xe tự lái hay chatbot. Ẩn sau những công nghệ tưởng chừng “kỳ diệu” ấy là một cấu trúc mô phỏng hoạt động của não người, được gọi là mạng nơ-ron nhân tạo (Artificial Neural Network – ANN). Đây chính là “trái tim” giúp máy tính có khả năng học hỏi, suy luận và thích nghi với dữ liệu.
Nội dung
Mô phỏng bộ não con người bằng công nghệ
Ý tưởng về mạng nơ-ron bắt nguồn từ việc mô phỏng hoạt động của tế bào thần kinh sinh học. Mỗi nơ-ron nhận tín hiệu từ nhiều tế bào khác, xử lý thông tin và chỉ phát tín hiệu khi đạt ngưỡng nhất định. Năm 1943, hai nhà khoa học Warren McCulloch và Walter Pitts đã đề xuất mô hình nơ-ron nhân tạo đầu tiên, mở ra hướng đi mới cho việc mô phỏng trí thông minh nhân tạo.
Khi hàng trăm, hàng nghìn nơ-ron nhân tạo được kết nối, chúng hình thành nên một mạng nơ-ron, có khả năng biểu diễn và xử lý những mối quan hệ dữ liệu phức tạp, tương tự cách con người tư duy và học hỏi.

Cấu trúc cơ bản của mạng nơ-ron
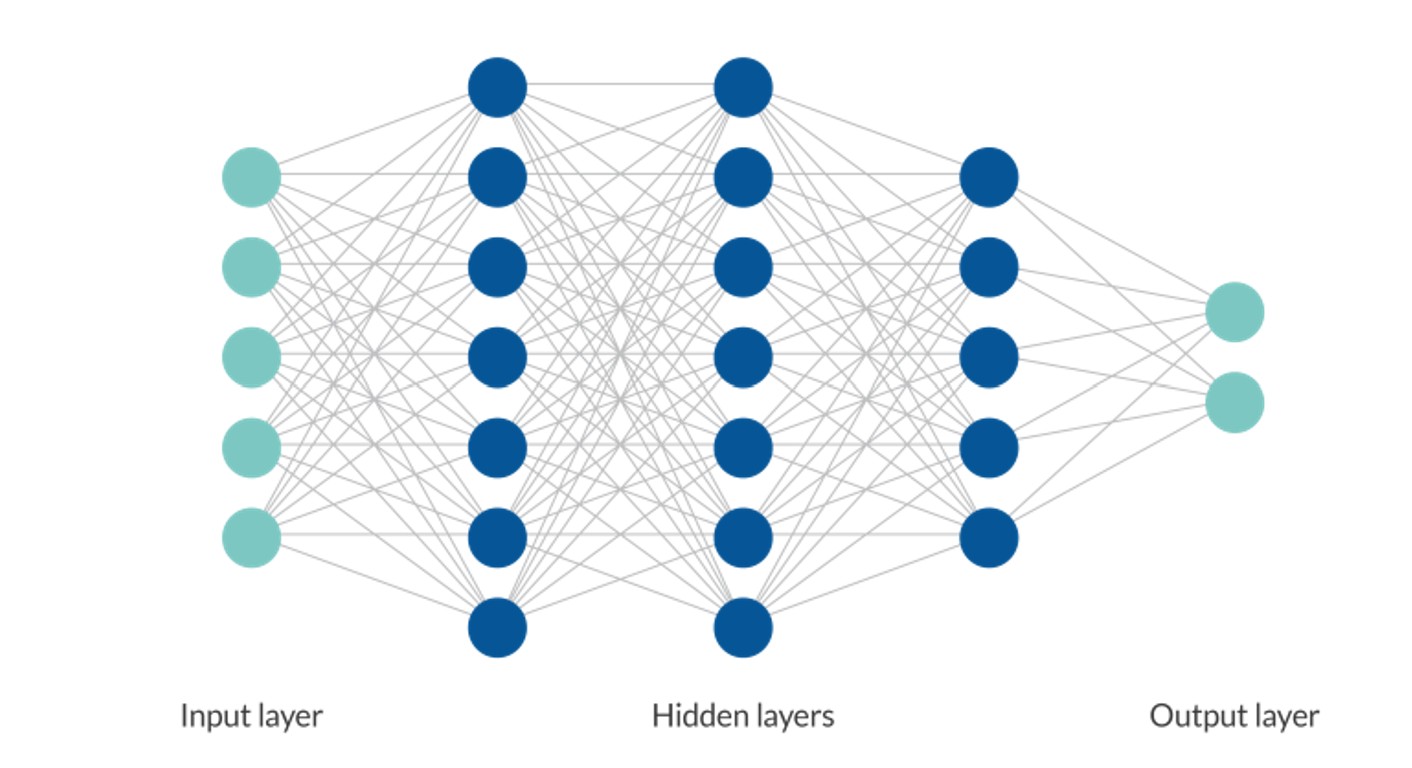
Một mạng nơ-ron thông thường gồm ba phần chính:
Tầng đầu vào (Input Layer): nhận dữ liệu đầu vào như hình ảnh, văn bản, hoặc số liệu.
Tầng ẩn (Hidden Layers): nơi diễn ra quá trình trích xuất đặc trưng và học các mối quan hệ giữa dữ liệu.
Tầng đầu ra (Output Layer): đưa ra kết quả dự đoán, chẳng hạn xác định một hình ảnh là “mèo” hay “chó”.
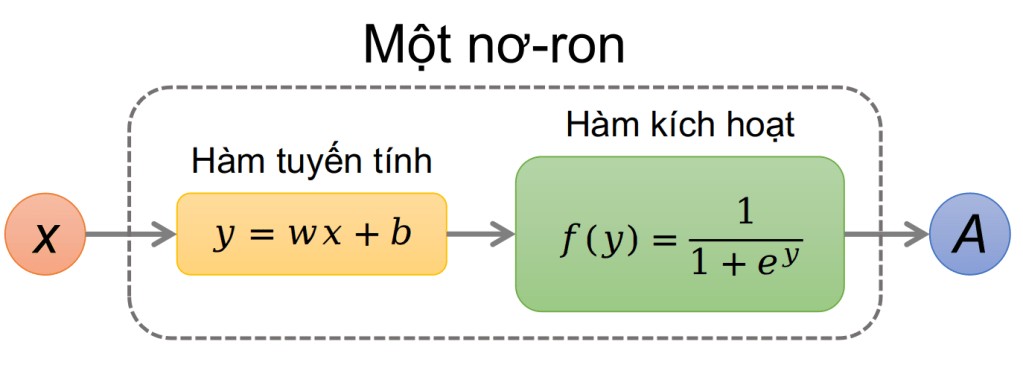
Mỗi kết nối giữa hai nơ-ron có một trọng số (weight), thể hiện mức độ ảnh hưởng của tín hiệu. Một nơ-ron sẽ xử lý đầu vào, cộng với trọng số và hệ số điều chỉnh (bias), sau đó truyền kết quả qua hàm kích hoạt (activation function) để xác định có “phát tín hiệu” hay không.
Cơ chế huấn luyện – Cách AI “học” từ dữ liệu
Khi nói “AI học”, thực chất là quá trình tối ưu hóa trọng số trong mạng để dự đoán của hệ thống ngày càng chính xác hơn. Toàn bộ quy trình huấn luyện (training) gồm các bước chính:
Chuẩn bị dữ liệu: AI học từ dữ liệu đã gắn nhãn (ví dụ: hàng ngàn ảnh mèo và chó).
Lan truyền thuận (Forward Propagation): dữ liệu đi qua các tầng của mạng, tạo ra dự đoán ban đầu.
Tính sai số (Loss): so sánh kết quả dự đoán với giá trị thực, xác định độ chênh lệch.
Lan truyền ngược (Backpropagation): mạng điều chỉnh trọng số dựa trên sai số để giảm thiểu lỗi trong lần học tiếp theo.
Đánh giá và kiểm thử: mạng được thử nghiệm với dữ liệu mới để đánh giá khả năng “hiểu” thực sự, thay vì chỉ “nhớ” dữ liệu đã học.
Quá trình này lặp lại hàng ngàn, thậm chí hàng triệu lần, giúp mô hình dần “học được” các đặc trưng của dữ liệu và đưa ra dự đoán chính xác.
Khi máy tính học như con người
Giả sử bạn muốn dạy AI phân biệt mèo và chó. Ban đầu, mạng dự đoán sai hầu hết các ảnh. Nhưng sau mỗi lần sai, hệ thống sẽ tự điều chỉnh để “học kinh nghiệm”. Càng xem nhiều ảnh, AI càng nhận diện chính xác hơn, hiểu rằng “tai nhọn, mắt tròn, lông mềm” thường là đặc trưng của mèo. Đó chính là cách máy tính học từ trải nghiệm – giống như con người.
Cơ chế huấn luyện chính là linh hồn của trí tuệ nhân tạo. Cùng một cấu trúc mạng, nhưng với dữ liệu và phương pháp training khác nhau, kết quả có thể khác biệt hoàn toàn. Vì vậy, phần lớn công việc của kỹ sư AI không nằm ở việc “viết mạng”, mà là ở chuẩn bị dữ liệu và tinh chỉnh quá trình huấn luyện.
Mạng nơ-ron nhân tạo là sự giao thoa giữa sinh học, toán học và sức mạnh tính toán. Nó không thông minh bẩm sinh, mà trở nên thông minh nhờ hàng triệu lần học hỏi và điều chỉnh từ dữ liệu thực tế.
Hiểu rõ cách mạng nơ-ron được huấn luyện chính là bước đầu tiên để sinh viên công nghệ thông tin hiểu được cách các hệ thống như ChatGPT, Gemini, Copilot hay xe tự lái “học” và “thích nghi” với thế giới — mở ra cánh cửa khám phá những ứng dụng AI tiên tiến trong tương lai.
Giảng viên Trịnh Quang Hòa
| FPT Aptech trực thuộc Tổ chức Giáo dục FPT có hơn 25 năm kinh nghiệm đào tạo lập trình viên quốc tế tại Việt Nam, và luôn là sự lựa chọn ưu tiên của các sinh viên và nhà tuyển dụng. |


