Trong kỷ nguyên công nghệ số hiện nay, việc tìm kiếm thông tin trở nên vô cùng quan trọng và cần thiết đối với mọi lĩnh vực của cuộc sống. Từ nghiên cứu khoa học, kinh doanh, giáo dục cho đến giải trí, nhu cầu về việc tiếp cận thông tin nhanh chóng và chính xác ngày càng tăng. Trí tuệ nhân tạo tạo sinh (Generative AI – GenAI) hay còn gọi ngắn gọn là “AI tạo sinh” đã và đang được ứng dụng rộng rãi để đáp ứng nhu cầu này, đem lại những đột phá mới mẻ và hiệu quả.
Nội dung
AI tạo sinh là gì?
AI tạo sinh là hệ thống AI có khả năng tạo ra văn bản, hình ảnh hay các phương tiện truyền thông khác dựa trên các dữ liệu đã học. Các mô hình AI tạo sinh sẽ học các mô hình và cấu trúc dữ liệu đầu vào của chúng bằng cách áp dụng các kỹ thuật học máy, mô hình học sâu (deep learning), mạng nơ-ron nhân tạo (neural networks), đặc biệt là các mô hình lớn như GPT (Generative Pre-trained Transformer) của OpenAI, và sau đó tạo ra dữ liệu mới có các đặc điểm tương tự [1].
AI tạo sinh có mức độ tác động rất sâu rộng đối với kinh tế – xã hội, chính trị, an ninh của các quốc gia trên thế giới. Việc ứng dụng AI nói chung, AI tạo sinh nói riêng vào các hoạt động kinh tế, giúp tối ưu hóa quy trình kinh doanh, nâng cao năng suất, gia tăng giá trị rất lớn. Dự kiến quy mô thị trường AI thế giới sẽ đạt 407 tỷ USD vào năm 2027; tỷ lệ tăng trưởng hàng năm ước tính của AI trong giai đoạn 2023 – 2030 sẽ là 37,3%.

Tại Việt Nam, việc phát triển công nghệ AI được ưu tiên trong chính sách phát triển. “Chiến lược Quốc gia về nghiên cứu, phát triển và ứng dụng AI đến năm 2030” được ban hành năm 2021. Việt Nam là một trong số 60 nước đã đưa ra chiến lược quốc gia về AI. Chỉ số sẵn sàng AI toàn cầu của Việt Nam hiện đứng thứ 59/193 quốc gia/vùng lãnh thổ.
Các doanh nghiệp công nghệ Việt Nam đang dần bắt kịp xu hướng, nhiều nền tảng ứng dụng AI tạo sinh được giới thiệu, như hệ thống GenAI của Tập đoàn FPT; ViGPT, VinBase 2.0 của Công ty cổ phần VinBigData (Vingoup); “PhởGPT” của công ty VinAI. Tính đến thời điểm hiện tại Việt Nam có 4 “kỳ lân” công nghệ gồm VNG, VNPAY, Momo, Sky Mavis. Việt Nam có nhiều chuyên gia nổi tiếng về AI như Nguyễn Hồng Đăng, TS. Lương Minh Thắng, Nguyễn Xuân Phong… [2]
Lợi ích của AI tạo sinh trong tìm kiếm thông tin
AI tạo sinh (GenAI – viết tắt từ Generative AI) đem lại nhiều lợi ích quan trọng trong việc tìm kiếm thông tin:
Tăng tốc độ tìm kiếm: Với khả năng xử lý và phân tích dữ liệu khổng lồ trong thời gian ngắn, GenAI giúp tăng tốc độ tìm kiếm thông tin, giúp người dùng nhanh chóng tiếp cận được thông tin cần thiết.
Cải thiện độ chính xác: GenAI có thể hiểu ngữ cảnh và ý nghĩa của các truy vấn tìm kiếm, từ đó cung cấp các kết quả tìm kiếm chính xác và phù hợp hơn so với các công cụ tìm kiếm truyền thống.
Khả năng cá nhân hóa: GenAI có khả năng học hỏi từ thói quen và sở thích của người dùng, từ đó cung cấp các gợi ý tìm kiếm và thông tin được cá nhân hóa, nâng cao trải nghiệm người dùng.
Tạo ra nội dung mới: Ngoài việc tìm kiếm thông tin hiện có, GenAI còn có khả năng tạo ra nội dung mới, giúp bổ sung và mở rộng kiến thức cho người dùng.

Cách thức hoạt động của AI tạo sinh
GenAI hoạt động chủ yếu thông qua mô hình học máy có khả năng tạo ra dữ liệu mới có cấu trúc và ý nghĩa. Có nhiều mô hình hoạt động khác nhau tùy thuộc vào những lĩnh vực riêng biệt.
Mô hình khuếch tán (Diffusion Model)
Mô hình khuếch tán tạo dữ liệu mới bằng cách lặp đi lặp lại việc thực hiện các thay đổi ngẫu nhiên có kiểm soát đối với mẫu dữ liệu ban đầu. Các mô hình này bắt đầu với dữ liệu gốc và thêm những thay đổi cực nhỏ (nhiễu), dần dần làm cho dữ liệu ít giống với bản gốc. Nhiễu này được kiểm soát cẩn thận để đảm bảo dữ liệu được tạo ra vẫn mạch lạc và thực tế.
Sau khi thêm nhiễu qua nhiều lần lặp lại, mô hình khuếch tán sẽ đảo ngược quá trình. Việc khử nhiễu ngược dần loại bỏ nhiễu để tạo ra một mẫu dữ liệu mới giống với bản gốc.
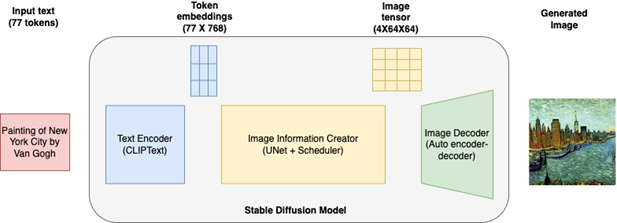
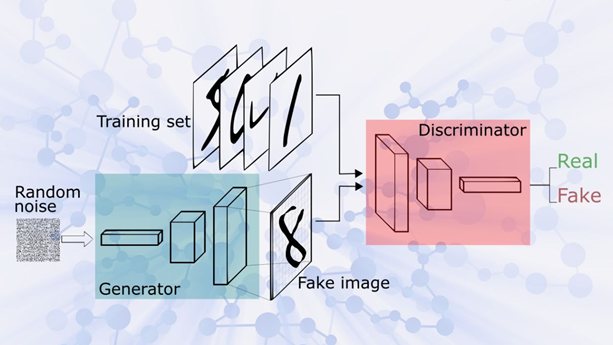
Mạng đối nghịch tạo sinh (Generative Adversarial Networks – GAN) [3]
Generator (Tạo sinh):
Nhiệm vụ: Tạo ra dữ liệu mới từ tín hiệu nhiễu (noise) ngẫu nhiên.
Hoạt động: Generator nhận đầu vào là các điểm ngẫu nhiên sinh ra bằng cách thay đổi nhiễu và tạo ra dữ liệu mới, thường là hình ảnh, văn bản, hoặc các định dạng khác. Mục tiêu của Generator là tạo ra dữ liệu sao cho nó trông giống với dữ liệu thực tế nhất có thể.
Discriminator (Phân biệt):
Nhiệm vụ: Đánh giá xem một mẫu dữ liệu là thật (đến từ tập dữ liệu đào tạo) hay giả tạo (tạo ra bởi Generator).
Hoạt động: Discriminator nhận dữ liệu và phân loại nó thành hai loại: thật (đúng) hoặc giả tạo (sai). Discriminator được huấn luyện để ngày càng trở nên tinh tế hơn trong việc phân biệt giữa dữ liệu thật và giả tạo.
Kỹ thuật GenAI trong tìm kiếm thông tin
Để tìm hiểu về kỹ thuật tìm kiếm thông tin của GenAI, chúng ta cần xem xét 4 vấn đề sau:
Mô hình ngôn ngữ tự nhiên (Natural Language Models)
Các mô hình ngôn ngữ tự nhiên như GPT-4 của OpenAI có khả năng hiểu và tạo ra ngôn ngữ tự nhiên giống như con người. Những mô hình này được huấn luyện trên lượng dữ liệu văn bản khổng lồ, cho phép chúng nắm bắt ngữ nghĩa và ngữ cảnh của các từ và câu.
Ví dụ: Khi bạn nhập câu truy vấn như “Làm thế nào để cải thiện hiệu suất tìm kiếm trong ứng dụng thương mại điện tử?”, mô hình GPT-4 có thể tạo ra câu trả lời chi tiết dựa trên kiến thức đã học.
Kỹ thuật học sâu (Deep Learning Techniques)
Học sâu là một phân nhánh của học máy (machine learning) sử dụng các mạng nơ-ron nhân tạo nhiều lớp để học và mô phỏng các mẫu dữ liệu phức tạp. Các mạng nơ-ron hồi quy (Recurrent Neural Networks – RNN) và mạng nơ-ron tích chập (Convolutional Neural Networks – CNN) là hai kỹ thuật học sâu phổ biến trong GenAI.
Ví dụ: RNN có thể được sử dụng để dự đoán chuỗi thời gian hoặc xử lý ngôn ngữ tự nhiên, trong khi CNN thường được sử dụng trong việc xử lý hình ảnh và video.

Huấn luyện trước và tinh chỉnh
Quá trình huấn luyện trước (Pre-training) giúp mô hình học các mẫu ngữ pháp và ngữ nghĩa từ lượng dữ liệu lớn, trong khi tinh chỉnh (Fine-tuning) cho phép mô hình điều chỉnh và tối ưu hóa dựa trên các nhiệm vụ cụ thể.
Ví dụ: Mô hình GPT-4 được huấn luyện trước trên hàng tỷ từ từ nhiều nguồn khác nhau, sau đó tinh chỉnh trên các nhiệm vụ cụ thể như trả lời câu hỏi, dịch thuật hay tạo nội dung.
Học tăng cường
Học tăng cường (Reinforcement Learning) giúp mô hình cải thiện hiệu suất bằng cách nhận phản hồi từ môi trường và điều chỉnh hành vi dựa trên phần thưởng hay hình phạt.
Ví dụ: Chatbot sử dụng học tăng cường để tối ưu hóa các cuộc trò chuyện, cải thiện trải nghiệm người dùng thông qua phản hồi tích cực hoặc tiêu cực từ người dùng.
Các bước xây dựng hệ thống tìm kiếm thông tin
Có 3 bước để xây dựng hệ thống tìm kiếm thông tin của GenAI:
Lựa chọn mô hình GenAI phù hợp
Một trong những bước quan trọng đầu tiên là lựa chọn mô hình GenAI phù hợp. Các mô hình như GPT-4 của OpenAI là lựa chọn phổ biến vì khả năng xử lý ngôn ngữ tự nhiên xuất sắc.
Chuẩn bị dữ liệu huấn luyện
Việc chuẩn bị dữ liệu huấn luyện là yếu tố then chốt. Dữ liệu này có thể bao gồm văn bản từ nhiều nguồn khác nhau để mô hình có thể học được cách hiểu và tạo ra ngữ cảnh phù hợp.

Huấn luyện và tinh chỉnh mô hình
Quá trình huấn luyện trước giúp mô hình học các mẫu ngữ pháp và ngữ nghĩa cơ bản. Sau đó, tinh chỉnh mô hình trên các nhiệm vụ cụ thể để tối ưu hóa hiệu suất.
Xây dựng giao diện tìm kiếm
Thiết kế giao diện người dùng cho hệ thống tìm kiếm là bước quan trọng để đảm bảo trải nghiệm người dùng mượt mà và thân thiện.
Ví dụ minh họa tìm kiếm sản phẩm trong ứng dụng thương mại điện tử
1. Tập tin dữ liệu minh họa: products.csv
product_id,product_name,product_description,category
1,Laptop,Compact microwave with various settings,electronics
2,Smartphone,Compact microwave with various settings,kitchen appliances
3,Microwave,All-in-one wireless printer,kitchen appliances
4,Blender,All-in-one wireless printer,electronics
5,Blender,Smartwatch with fitness tracking capabilities,electronics
2. Cài đặt thư viện
pip install fastapi, numpy, tensorflow, tf-keras, transformers, uvicorn, pandas, scikit-learn
3. Đọc dữ liệu từ file
data = pd.read_csv(‘products.csv’)
4. Tiền xử lý dữ liệu
texts = data[‘product_description’].values
labels = data[‘category’].factorize()[0]
input_ids, attention_masks, labels = preprocess_data(texts, labels)
5. Tạo model cho việc tìm kiếm
class CustomModel(tf.keras.Model):
def __init__(self, bert_model):
super(CustomModel, self).__init__()
self.bert = bert_model
self.global_avg_pooling = tf.keras.layers.GlobalAveragePooling1D()
self.dense = tf.keras.layers.Dense(128, activation=’relu’)
self.classifier = tf.keras.layers.Dense(1, activation=’sigmoid’)
def call(self, inputs):
input_ids, attention_mask = inputs
outputs = self.bert(input_ids, attention_mask=attention_mask)[0]
x = self.global_avg_pooling(outputs)
x = self.dense(x)
return self.classifier(x)
custom_model = CustomModel(bert_model)
outputs = custom_model(inputs)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
6. Biên dịch model
model.compile(optimizer=’adam’, loss=’binary_crossentropy’, metrics=[‘accuracy’])
7. Huấn luyện model
model.fit(
[train_inputs, train_masks],
train_labels,
validation_data=([test_inputs, test_masks], test_labels),
epochs=3,
batch_size=32
)
8. Lưu model
model.save(‘models/my_model/1’)
Triển khai model này sử dụng tensorflow/serving thông qua docker
9. Tải docker image
docker pull tensorflow/serving
10. Chạy docker image
docker run -p 8501:8501 –name=tf_serving –mount type=bind,source=.\models\my_model,target=/models/my_model -e MODEL_NAME=my_model -t tensorflow/serving
11. Xây dựng api sử dụng FastApi
@app.post(“/predict/”)
async def predict(description: ProductDescription):
# Xây dựng dữ liệu từ tham số truyền vào
input_ids, attention_mask = preprocess_input(description.description)
# gọi api deploy bằng tensorflow/serving trên docker
response = requests.post(
‘http://localhost:8501/v1/models/my_model:predict’,
json={“instances”: [{“input_ids”: input_ids.numpy().tolist()[0], “attention_mask”: attention_mask.numpy().tolist()[0]}]}
)
if response.status_code != 200:
return {“error”: response.json()}
# Tính toán hệ số cho trường product_description của dữ liệu
product_descriptions = data[‘product_description’].tolist()
embeddings = get_embeddings(product_descriptions)
# Tính toán độ tương tự cosine
input_embedding = get_embeddings([description.description])
similarities = cosine_similarity(input_embedding, embeddings)
# Tìm sản phẩm tương tự nhất
most_similar_index = similarities.argmax()
most_similar_product = data.iloc[most_similar_index]
return {
“product”: most_similar_product.to_dict(),
“similarity_score”: float(similarities[0][most_similar_index]) # Convert numpy.float32 to float
}
12. Dùng curl hoặc postman để kiểm thử api
curl -X POST http://localhost:8000/predict/ -H “Content-Type: application/json” -d ‘{“description”: “This is a smartphone with 4GB RAM and 64GB storage”}’
Xem video chạy thử chương trình dưới đây:
TÀI LIỆU THAM KHẢO:
- https://vi.wikipedia.org/wiki/Trí_tuệ_nhân_tạo_tạo_sinh
- https://dangcongsan.vn/ban-doc/y-kien-ban-doc/ai-tao-sinh-bai-toan-phat-trien-va-quan-ly-660083.html
- https://aws.amazon.com/what-is/generative-ai/
Hoàng Đức Quang | Giảng viên FPT Aptech
| FPT Aptech trực thuộc Tổ chức Giáo dục FPT có hơn 25 năm kinh nghiệm đào tạo lập trình viên quốc tế tại Việt Nam, và luôn là sự lựa chọn ưu tiên của các sinh viên và nhà tuyển dụng. |


