Nếu giống như tôi, bạn là người hâm mộ các ứng dụng giúp cải thiện chất lượng cuộc sống và quan tâm đến điều gì khiến các ứng dụng này hoạt động tốt đến vậy, hãy thẽo dõi bài viết này để cùng tôi tìm hiểu về: Trí tuệ nhân tạo (Artificial Intelligence viết tắt là AI) và Học máy (Machine Learning viết tắt là ML).
Các ứng dụng sử dụng AI/ML bao gồm lọc thư rác trong tài khoản email của chúng tôi, sử dụng kỹ thuật ML để xác định và gắn cờ thư rác; hệ thống đề xuất trên nền tảng phát trực tuyến video, thương mại điện tử hoặc âm nhạc cũng sử dụng ML để đề xuất nội dung mà chúng tôi có thể quan tâm dựa trên lịch sử tương tác; nhận dạng giọng nói và dịch máy cũng dựa trên ML.
Nhưng bạn đã bao giờ tự hỏi AI thực sự là gì chưa? Còn ML thì sao? Tôi sẽ trả lời những câu hỏi đó và giải thích các giai đoạn tồn tại của các dự án ML, để lần tới khi bạn xây dựng một ứng dụng sử dụng một số dịch vụ dựa trên AI/ML mới, bạn sẽ hiểu điều gì đằng sau nó và điều gì khiến nó trở nên tuyệt vời như vậy.
Và đừng lo lắng, tôi sẽ không làm bạn chán môn Toán đâu!
Nội dung
Trí tuệ nhân tạo là gì?
Trí tuệ nhân tạo, hay AI, là kết quả nỗ lực trong việc tự động hóa các nhiệm vụ thường do con người thực hiện, chẳng hạn như nhận dạng mẫu hình ảnh, phân loại tài liệu hoặc thi đấu cờ vua trên máy vi tính.
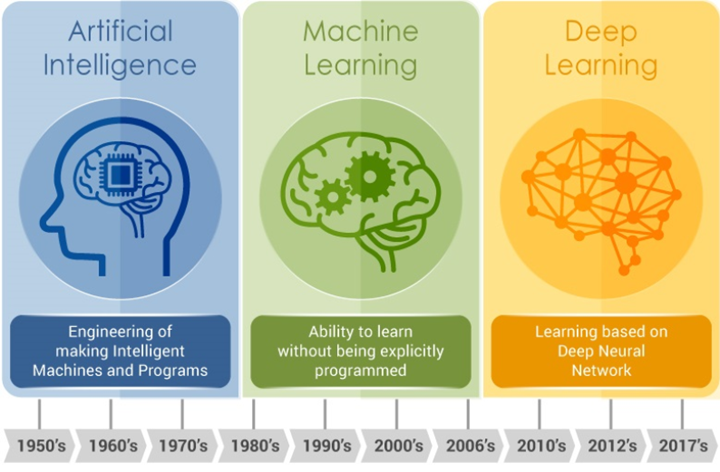
(Hình 1) AI bao gồm nhiều cách tiếp cận khác nhau: AI mang tính biểu tượng, còn được gọi là “good old-fashioned AI” (GOFAI), sử dụng các quy tắc được xác định rõ ràng và cách biểu diễn mang tính biểu tượng để giải quyết vấn đề.
Nó tương tự như lập trình truyền thống ở chỗ các nguyên tắc được xác định trước sẽ thúc đẩy quá trình, tuy nhiên, nó nâng cao hơn vì nó cho phép suy luận và thích ứng với các tình huống mới.
Machine Learning (ML) là một phương pháp AI khác cho phép các thuật toán học hỏi từ dữ liệu. Deep Learning (DL) là một tập hợp con của ML sử dụng mạng lưới thần kinh nhân tạo, nhiều lớp.
Học máy là gì?
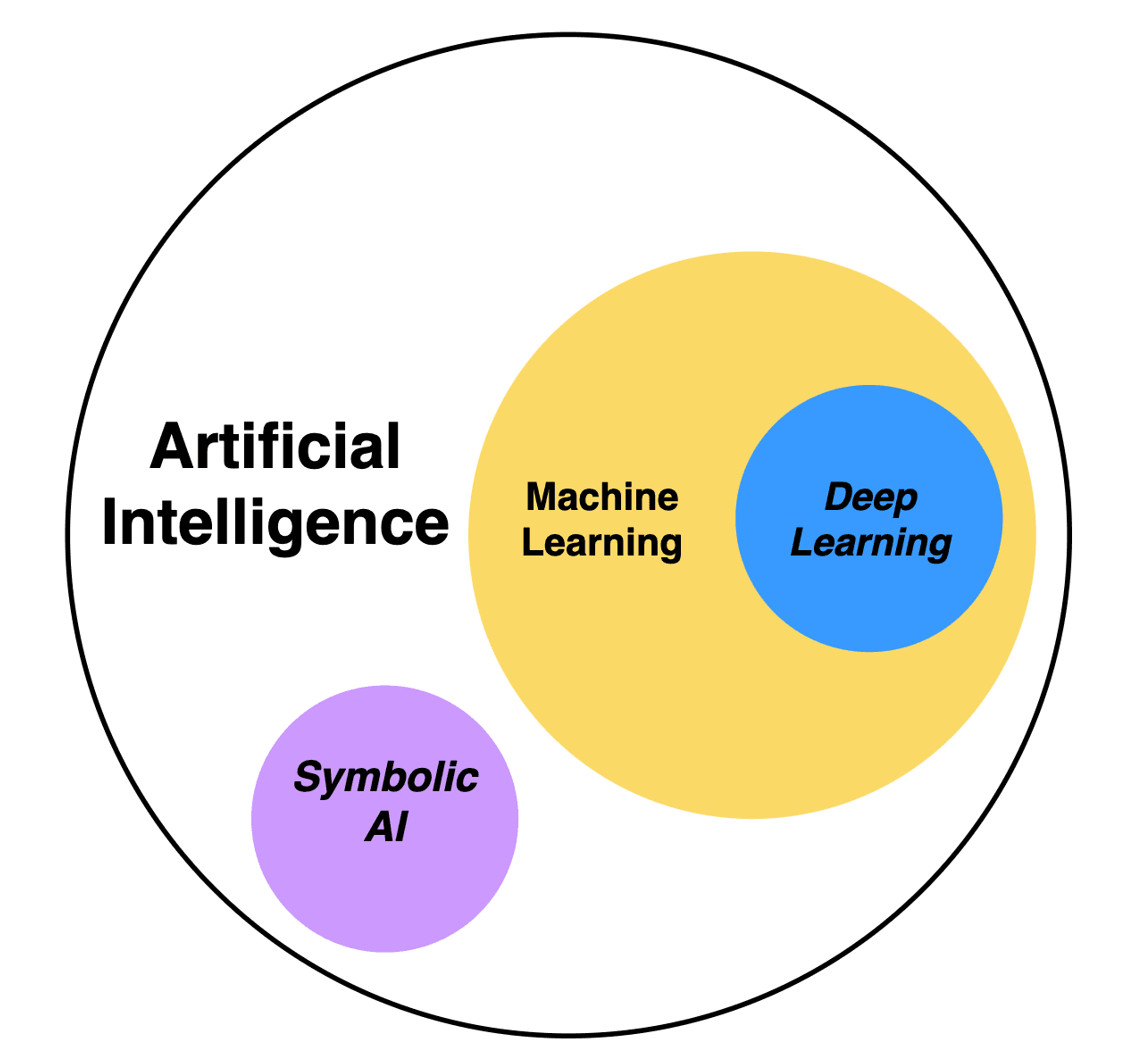
Machine Learning, hay ML, tập trung vào việc tạo ra các hệ thống hoặc mô hình có thể học từ dữ liệu và cải thiện hiệu suất của chúng trong các nhiệm vụ cụ thể mà không cần phải lập trình rõ ràng, khiến chúng học hỏi từ kinh nghiệm hoặc ví dụ trong quá khứ để đưa ra quyết định về dữ liệu mới. Điều này khác với lập trình truyền thống, trong đó các lập trình viên con người viết các quy tắc bằng mã, chuyển đổi dữ liệu đầu vào thành kết quả mong muốn (Hình 2).
Bây giờ, tôi sẽ giải thích các thuật ngữ chuyên dụng trong ML:
 | Mô hình (Model): Mô hình là sự biểu diễn giải thích các quan sát. Mô hình được đào tạo là kết quả của việc áp dụng thuật toán ML với tập dữ liệu. Mô hình đã được đào tạo này, hiện đã có sẵn các mẫu và hiểu biết cụ thể từ tập dữ liệu, sau đó được sử dụng để rút ra suy luận từ các quan sát mới.
|
 | Thuật toán (Algorithm): Thuật toán là một quy trình được triển khai bằng mã nhằm hướng dẫn mô hình học từ dữ liệu được cung cấp. Có rất nhiều thuật toán học máy.
|
 | Đào tạo (Training): Đào tạo là quá trình lặp đi lặp lại việc áp dụng thuật toán học tập. Bao gồm trong:
|
 | Kiểm tra (Testing): Đo lường hiệu suất của mô hình dữ liệu bằng cách sử dụng dữ liệu thử nghiệm chưa được đào tạo. |
 | Triển khai (Deployment): Tích hợp mô hình vào môi trường sản xuất. |
 | Tập dữ liệu (Dataset): Tập dữ liệu là nguyên liệu thô mà mô hình ML sử dụng và tương tác. Nó có thể bao gồm hình ảnh, văn bản, giá trị số và bất kỳ thứ gì khác có thể được kết hợp lại thành dữ liệu liên quan.
|
Mô hình học máy học như thế nào?
Để cho phép mô hình học hỏi, nó phải trải qua quá trình “đào tạo”. Điều này liên quan đến việc hiển thị dữ liệu để nó có thể hiểu và hình thành mối quan hệ giữa dữ liệu và kết quả mong đợi. Mối quan hệ này hình thành dưới dạng hệ số hoặc tham số, giống như cách chúng ta điều chỉnh bộ cân bằng âm nhạc để đạt được âm thanh tối ưu.
Để tìm hiểu các tham số này, ban đầu mô hình cần có một định nghĩa.
Hãy xem xét ví dụ này:
Mô hình (Model): Mối quan hệ giữa Centimet và Inch được tính bởi công thức:
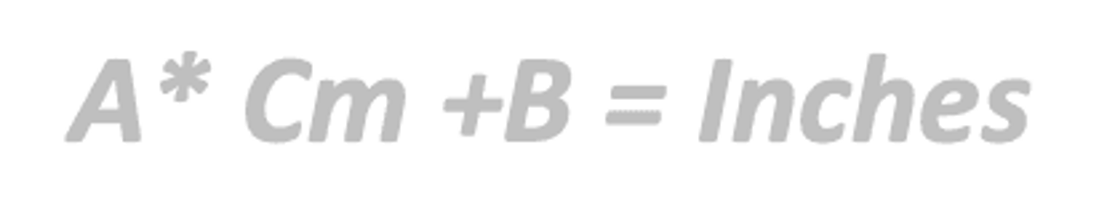
Quá trình học của mô hình bao gồm việc áp dụng thuật toán để rút ra các giá trị của A và B từ dữ liệu quan sát được là Centimet và Inch.
Thuật toán (Algorithm) này (được gọi là thuật toán ML) được áp dụng lặp đi lặp lại trên tất cả dữ liệu (đôi khi nhiều hơn một lần) để tìm tham số A và B. Sau vài lần lặp lại thuật toán, chúng ta có được một mô hình được đào tạo có khả năng khái quát hóa mối quan hệ giữa cm và inch cho bất kỳ quan sát mới nào.
Mô hình được đào tạo (Trained Model):
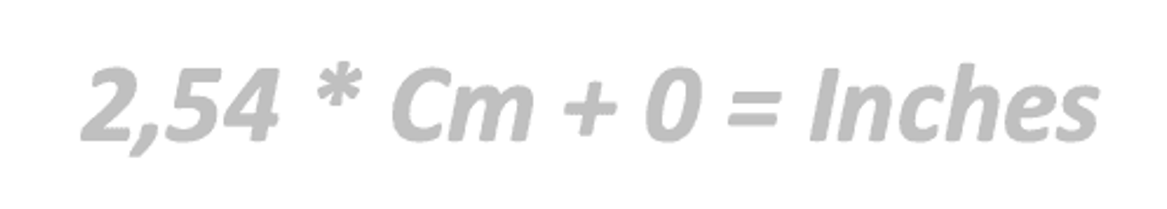
Nếu quay lại Hình 1, chúng ta sẽ thấy rằng Deep Learning (DL) nằm trong ML, điều này đặt ra một câu hỏi mới cần được trả lời.
Học sâu là gì?
Deep Learning là một kỹ thuật ML sử dụng mạng lưới thần kinh sâu để học từ dữ liệu.
Mạng nơ-ron là một loại mô hình học máy được tạo thành từ nhiều lớp nút kết nối với nhau và điều chỉnh khi chúng tiếp xúc với dữ liệu.
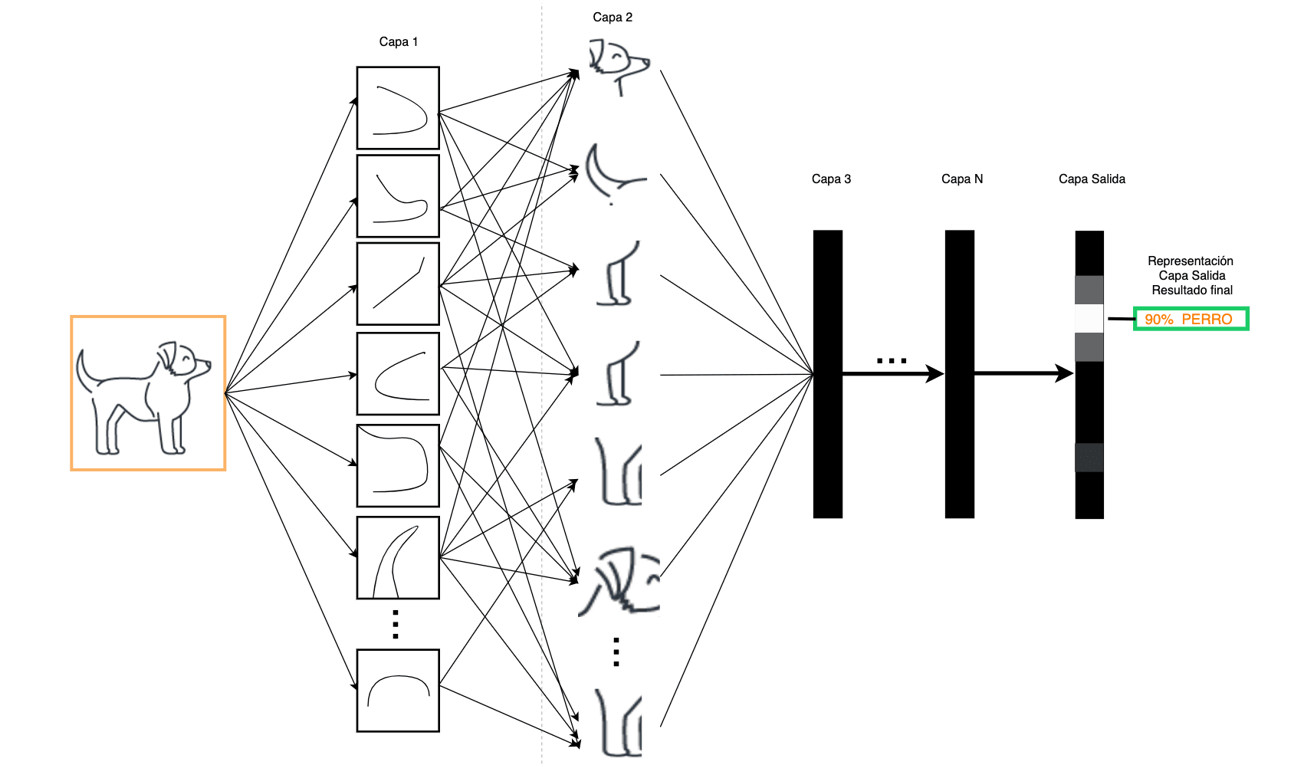
DL là học theo cấp bậc trong đó các lớp ban đầu học các biểu diễn cơ bản của dữ liệu được truyền đến lớp tiếp theo làm đầu vào. Các lớp này tạo ra thông tin mới, thông tin này được gửi đến lớp tiếp theo dưới dạng đầu vào, v.v.
Do đó, dữ liệu được xử lý và chắt lọc qua từng lớp, chuyển đổi dữ liệu thành dạng phù hợp cho lớp tiếp theo. Điều này cho phép nó tìm hiểu các khái niệm trừu tượng có liên quan chặt chẽ đến suy luận hoặc quyết định phải được đưa ra ở đầu ra, từ đó đưa ra dự đoán.
Trong ví dụ ở Hình 3, một hình ảnh được đưa vào mô hình đã huấn luyện: bộ phân loại động vật. Các lớp ban đầu tách một hình ảnh thành các phần nhỏ, thu được các biểu diễn cơ bản ngày càng trừu tượng và theo quá trình đào tạo trước đó của chúng, cho đến khi lớp đầu ra chỉ ra kết quả thu được: xác suất rằng đó là một con vật đã biết.
ML được chia thành nhiều loại hình học tập mà tôi sẽ giải thích như hình bên dưới:
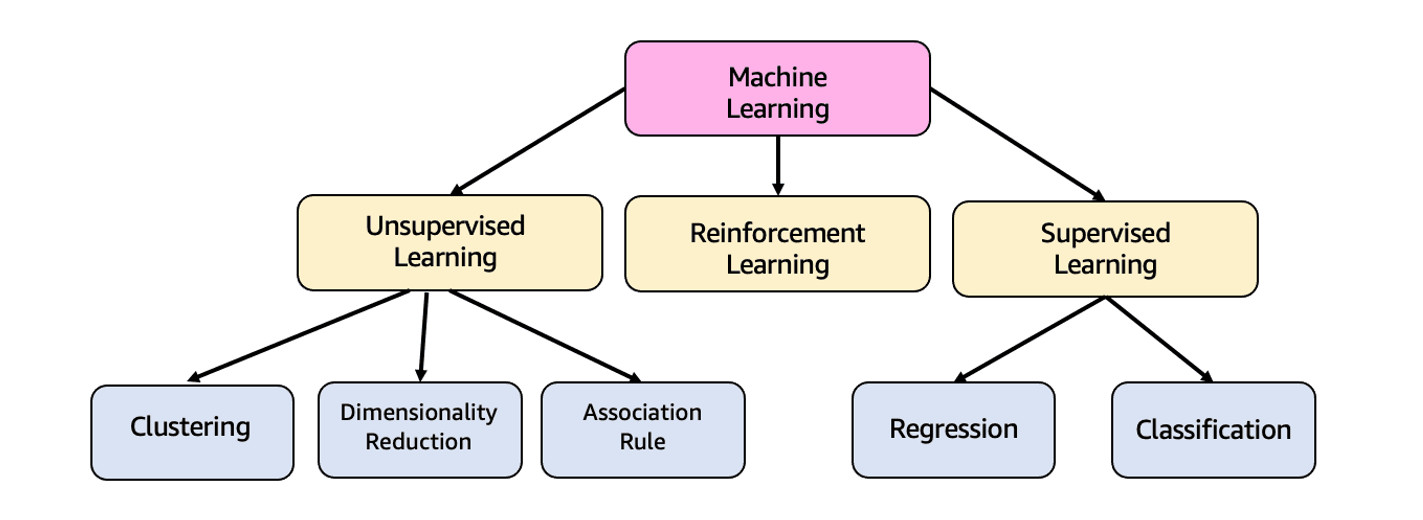
Học tập có giám sát (Supervised Learning)
Đây là loại hình học tập mà chúng ta đã nói đến cho đến nay. Đầu vào và đầu ra của mô hình, còn được gọi tương ứng là biến và nhãn, được sử dụng trong quá trình huấn luyện để khái quát hóa mô hình. Nó có thể học hỏi từ những sai lầm để cải thiện dự đoán. Nó được chia thành hai loại:
Hồi quy (Regression)
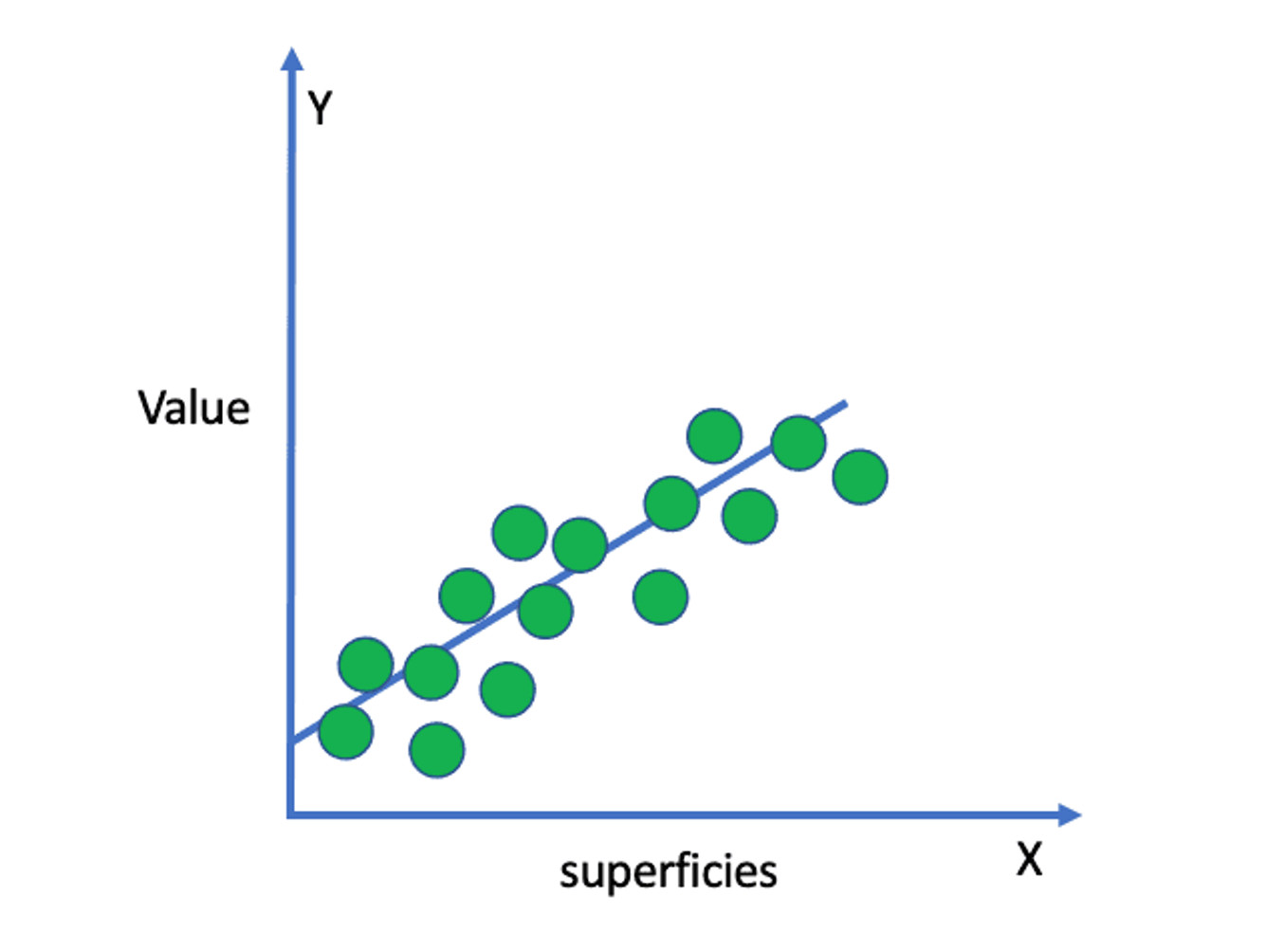
Điều này được sử dụng để dự đoán mối quan hệ giữa các biến độc lập và biến phụ thuộc. Nó dựa trên ý tưởng rằng biến phụ thuộc có thể được mô hình hóa như một sự kết hợp tuyến tính của các biến độc lập và một số hạng sai số.
Ví dụ, Hình 5 cho thấy một ví dụ đơn giản về cách giá trị của một thuộc tính tăng lên khi diện tích bề mặt của nó tăng lên, tạo ra mối quan hệ tuyến tính giữa cả hai đặc điểm.
Phân loại (Classification)
Điều này được sử dụng để gán dữ liệu cho một trong một số danh mục (lớp) dựa trên các đặc điểm nhất định. Khi trình phân loại đã được huấn luyện, nó có thể được sử dụng để đưa ra dự đoán về dữ liệu mới và chưa biết.
Phân loại nhị phân là một kiểu phân loại trong đó mỗi mẫu dữ liệu được gán vào một trong hai lớp loại trừ lẫn nhau. Mặt khác, phân loại nhiều lớp là nơi mỗi mẫu dữ liệu được gán vào một trong nhiều lớp (như ví dụ của chúng tôi về động vật trong Deep Learning).
Học không giám sát (Unsupervised Learning)
Không biết nhãn, mô hình sẽ khám phá các mẫu và cấu trúc trong dữ liệu. Nó được chia thành hai loại:
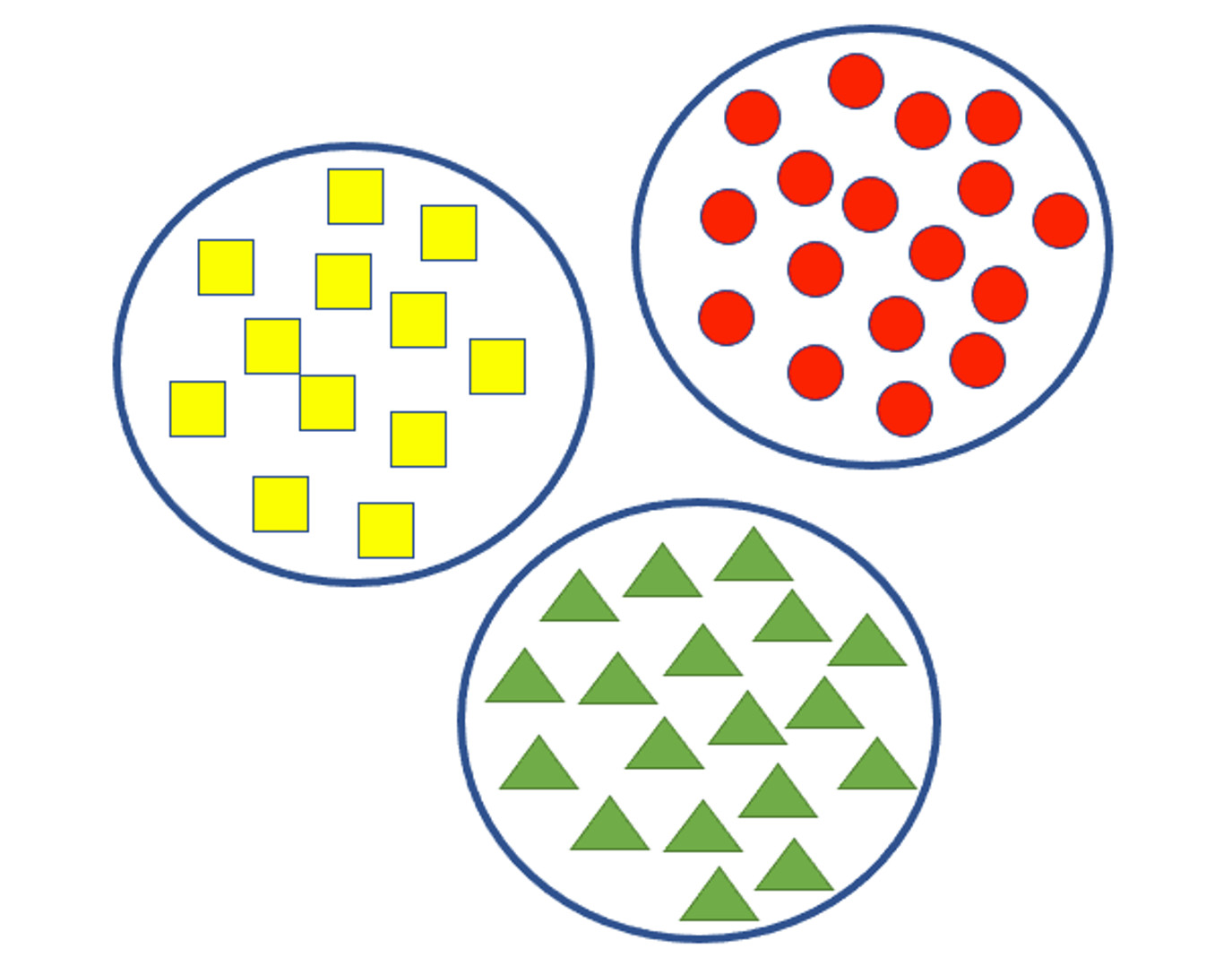
Clusterization
Đây là kỹ thuật dùng để chia tập dữ liệu thành các nhóm (cụm) dựa trên những đặc điểm nhất định. Dữ liệu trong cùng một cụm giống nhau hơn dữ liệu trong các cụm khác nhau.
Phân cụm thường được sử dụng để khám phá dữ liệu và phân tích nhóm. Ví dụ: Hình 6.
Giảm kích thước (Dimensionality Reduction)
Đây là một kỹ thuật được sử dụng trong học máy để giảm số lượng tính năng (biến) trong tập dữ liệu, đồng thời giữ lại thông tin quan trọng nhất. Điều này đạt được bằng cách loại bỏ các tính năng dư thừa hoặc không liên quan, cho phép các mô hình học máy được đào tạo nhanh hơn và đạt kết quả tốt hơn.
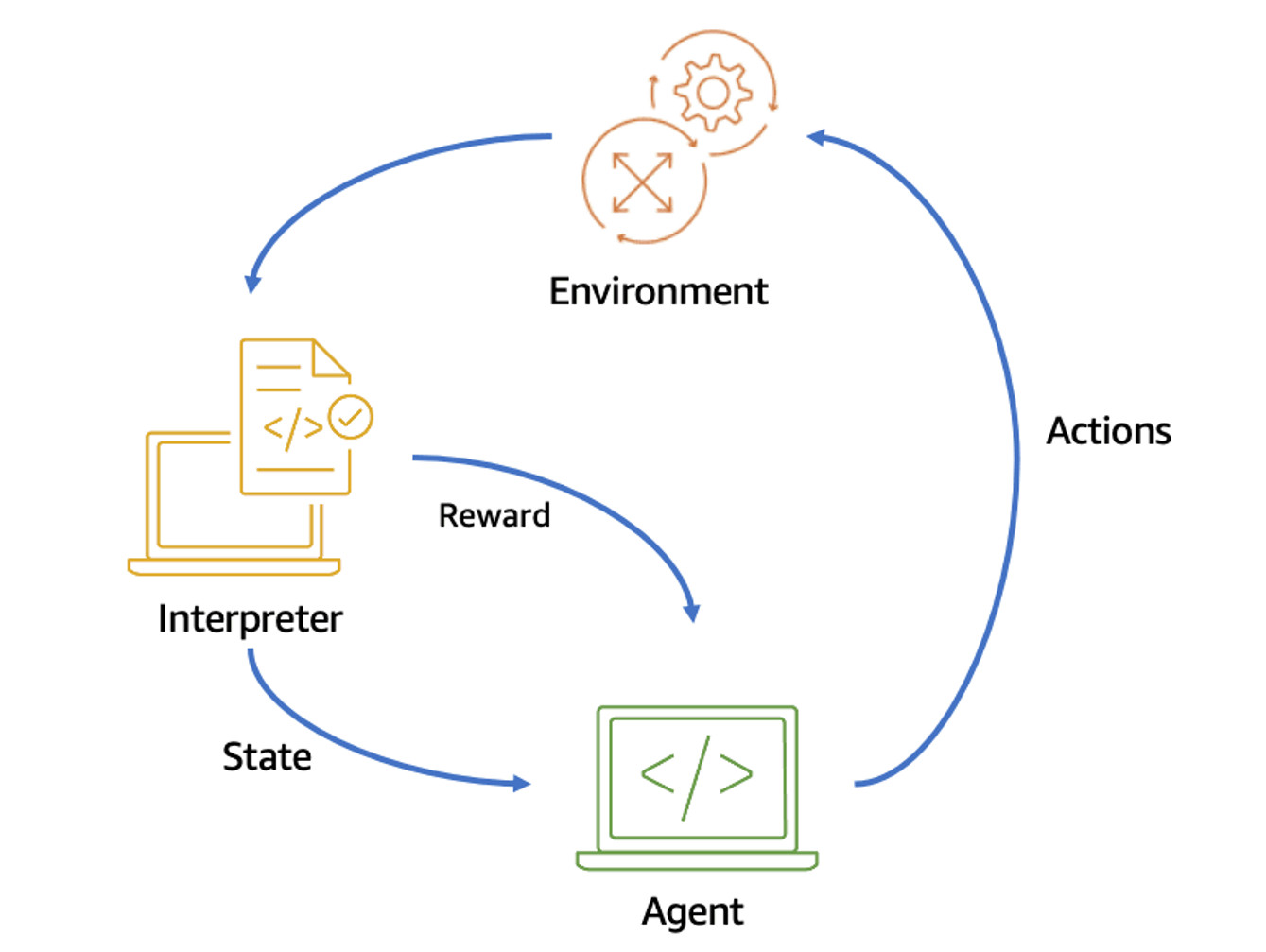
Học tăng cường (Reinforcement learning)
Đây là một kỹ thuật (Hình 7) trong đó tác nhân tương tác với môi trường của nó và nhận phần thưởng hoặc hình phạt dựa trên hành động của nó. Đặc vụ học hỏi thông qua khám phá và thử nghiệm, cố gắng tối đa hóa tổng phần thưởng nhận được theo thời gian. Điều này được thực hiện bằng cách chọn các hành động mà tác nhân tin rằng có nhiều khả năng tạo ra phần thưởng nhất.
Một ví dụ về AWS Deep Racer, nơi các mô hình được đào tạo để cạnh tranh trong các cuộc đua với tư cách là những chiếc ô tô trong đường đua (ảo hoặc vật lý).
Bây giờ chúng ta đã hiểu rõ hơn về AI/ML là gì và cách thức hoạt động của nó, chúng ta có thể tiếp cận một dự án ML bằng cách xác định các giai đoạn trong vòng đời ML.
Các giai đoạn trong vòng đời của một dự án học máy
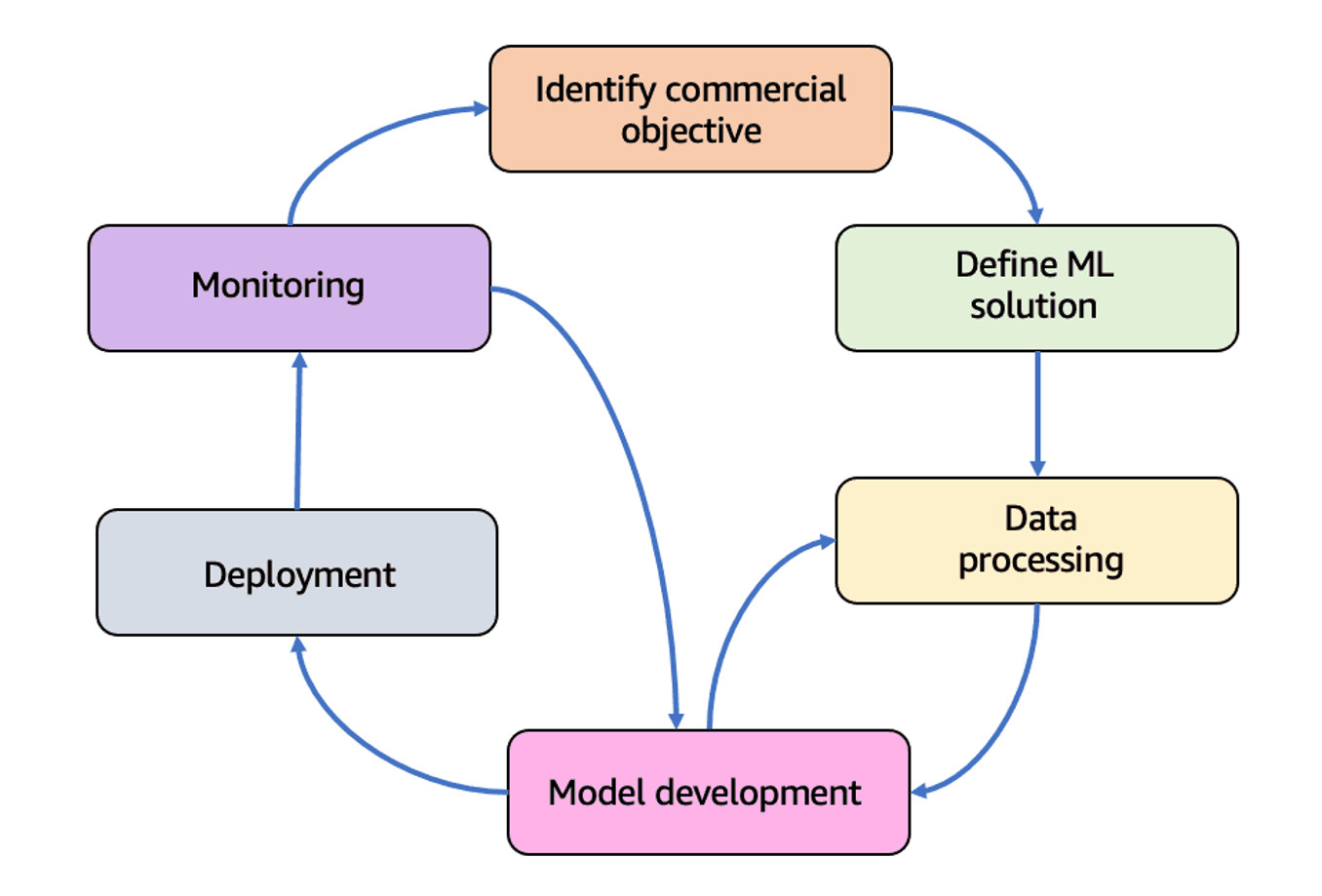
Vòng đời ML là một quá trình lặp đi lặp lại và có tính chu kỳ (như được mô tả trong Hình 8) mang lại sự rõ ràng và hiểu biết sâu sắc về toàn bộ quá trình, cấu trúc nó để tối đa hóa sự thành công của một dự án ML.
Cách tốt nhất để học là thông qua các ví dụ và thực hành. Mặc dù bảng ví dụ bên dưới không cung cấp mã nguồn nhưng chúng ta sẽ khám phá các giai đoạn của quá trình này bằng cách giả sử chúng ta muốn xây dựng một mô hình để phát hiện gian lận ngân hàng:
Giai đoạn (Phases) | Trong mô hình đánh giá gian lận ngân hàng |
| Xác định mục tiêu thương mại: Đây là giai đoạn quan trọng. Chúng ta phải có một vấn đề cần giải quyết, một giá trị có thể đo lường được cho hoạt động kinh doanh và các tiêu chí thành công. Bạn phải tự hỏi, có cần thiết phải sử dụng ML để giải quyết vấn đề này không? Các giải pháp ML không chỉ yêu cầu dữ liệu mà bạn còn phải đánh giá năng lực của tổ chức và sắp xếp các nhà lãnh đạo. | Trong trường hợp này, mục tiêu kinh doanh là giảm gian lận trong giao dịch ngân hàng. Tỷ lệ gian lận giảm X điểm phần trăm có nghĩa là chi phí hoàn trả được cải thiện Y và sự hài lòng của khách hàng được cải thiện Z. |
| Xác định giải pháp ML: Nếu chúng ta đang ở giai đoạn này, đó là vì chúng ta đã xác định rằng vấn đề của mình có thể được giải quyết bằng ML, đồng thời các chỉ số hiệu suất cũng như tiêu chí thành công đã được xác định. Chiến lược thu thập và ghi nhãn dữ liệu đã được tạo ra. | Được giám sát – Mô hình phân loại (Supervised – Classifier) hiện phải được chọn và nó phải xác định chính xác 85% giao dịch gian lận để đáp ứng mục tiêu của chúng tôi. Sai số phân loại giao dịch gian lận là chính xác không quá 10%. Dữ liệu sẽ là lịch sử của các giao dịch có nhãn “lừa đảo” – “hợp pháp” và cả thông tin khách hàng ẩn danh. |
| Xử lý dữ liệu: Điều này có nghĩa là dữ liệu có sẵn phải được xác định (sự kiện, chuỗi thời gian, thiết bị IoT, sự kiện trên mạng xã hội, v.v.) và thu được. Sau khi xác định được việc nhập và tổng hợp, chúng phải được dán nhãn và chuẩn bị giới thiệu cũng như sử dụng chúng trong mô hình học tập. | Thiết lập các quy trình nhập và xử lý dữ liệu để xây dựng tập dữ liệu huấn luyện và kiểm tra. |
| Phát triển mô hình – Triển khai: Bây giờ chúng tôi đưa mô hình ML đã được đào tạo, điều chỉnh và đánh giá vào sản xuất để đưa ra suy luận. Trong giai đoạn này, chúng ta phải xác định chiến lược triển khai, cơ sở hạ tầng mà mô hình sẽ vận hành, kiểu độ trễ suy luận (thời gian thực, không đồng bộ hoặc hàng loạt) và cách cung cấp mô hình đó cho các ứng dụng. | Tập trung vào cơ sở hạ tầng có khả năng hỗ trợ suy luận trong thời gian thực, bởi vì chúng tôi muốn xem xét các giao dịch tại thời điểm chúng được thực hiện và có thể chặn gian lận trước khi nó tiến triển. Ví dụ: dịch vụ web sẽ được gọi tại thời điểm giao dịch. |
| Giám sát: Chúng tôi xác định các quy tắc để phát hiện vấn đề và gửi cảnh báo. Các vấn đề cần phát hiện trong giai đoạn này bao gồm chất lượng dữ liệu và mô hình, độ lệch sai lệch và các vấn đề khác. Nếu cần thiết, mô hình nên được đào tạo lại. | Kiểm tra xem dữ liệu đến với chúng tôi có giống về mặt thống kê với dữ liệu đã đào tạo mô hình hay không. Chúng tôi cũng phải đưa ra các suy luận và kết quả cuối cùng của giao dịch dưới dạng báo cáo hoặc bảng trực quan (nghĩa là điều quan trọng là phải xác nhận rằng dự án đang đáp ứng các mục tiêu). Một hành động khác ở giai đoạn này là sử dụng các chuyên gia để xem xét các giao dịch đáng ngờ nhằm giúp xác định một cách hiệu quả mức độ gian lận và cung cấp dữ liệu mới cho mô hình để đào tạo lại. |
Điều quan trọng nhất của những mô hình này (ngoài việc có hiệu suất tuyệt vời) là những người sử dụng nó tin tưởng vào nó. Ví dụ: điều gì sẽ xảy ra nếu một khách hàng thực hiện giao dịch mua hàng hợp pháp và mô hình cho rằng hành động đó là lừa đảo bằng cách chặn thẻ của họ? Chúng tôi sẽ có một khách hàng tức giận muốn thay đổi ngân hàng.
Luôn nghĩ về khách hàng của bạn, làm thế nào để cung cấp cho họ dịch vụ tốt nhất, làm thế nào để cải thiện chất lượng cuộc sống của họ hay đơn giản là làm thế nào để làm cho họ hài lòng, bởi vì khách hàng không nhất thiết phải là người mà bạn nhận được phần thưởng bằng tiền hoặc một khu vực trong tổ chức của bạn; khách hàng cũng có thể là gia đình của bạn, những người sẽ thích một số ứng dụng mới mà bạn với tư cách là nhà phát triển, hiện có kiến thức về AI/ML, đã tạo cho họ.
Kết luận
Tôi hy vọng bạn thích bài đọc này và nó khiến bạn tò mò muốn phát triển nhiều ứng dụng hơn, đặc biệt là bây giờ bạn đã biết câu trả lời cho các câu hỏi: Trí tuệ nhân tạo là gì? Học máy là gì? Và mô hình ML học như thế nào?
Chúng tôi đã đi sâu vào khái niệm ML, khám phá các loại hình học tập, khám phá một tập hợp con ML được gọi là Deep Learning và cuối cùng, xem qua các giai đoạn của một dự án ML bằng cách sử dụng ví dụ phát hiện gian lận ngân hàng.
Từ giờ trở đi, mỗi khi bạn sử dụng AI/ML trong một ứng dụng, bạn sẽ biết rằng mô hình ML nào phù hợp với mình và bạn có thể xác định loại hình học tập đó là gì.
TÀI LIỆU DỊCH THUẬT
- https://community.aws/content/2drbbXokwrIXivItJ8ZeCk3gT5F/introduction-to-artificial-intelligence-and-machine-learning
- Deep Learning with Python, Second Edition – Author François Chollet
- AWS Well-Architected machine learning lens
- Architect and build the full machine learning lifecycle with AWS: An end-to-end Amazon SageMaker demo
- SkillBuilder Machine Learning plan
- What is ai?
- MLU-EXPLAIN
Trương Thành Trung | Giảng viên FPT Aptech
| FPT Aptech trực thuộc Tổ chức Giáo dục FPT có hơn 25 năm kinh nghiệm đào tạo lập trình viên quốc tế tại Việt Nam, và luôn là sự lựa chọn ưu tiên của các sinh viên và nhà tuyển dụng. |


